Processing, transforming, and delivering data to various destinations for analysis, reporting, and decision-making purposes is crucial for organizations that collect and generate vast amounts of data. Data pipelines play a significant role in enabling a smooth and efficient flow of data throughout an organization’s systems.
In simple terms, a data pipeline is a series of steps and processes that extract data from different sources, transform it into a desired format, and load it into a target destination or system. These pipelines automate the movement of data, ensuring that it is reliable, consistent, and readily available for analysis and consumption.
In this article, we will delve into some frequently asked questions about data pipelines and their importance in data engineering.
Why are data pipelines important?
Data pipelines facilitate the seamless flow of data from various sources, ensuring that data is collected, transformed, and delivered to the right destination in a timely manner. By providing a structured framework for data ingestion, processing, and transformation, data pipelines improve data quality, consistency, and reliability, enabling organizations to make informed decisions based on accurate and up-to-date information. Moreover, data pipelines automate repetitive tasks, reduce manual errors, and enhance operational efficiency, allowing data scientists, analysts, and other stakeholders to focus on extracting insights and driving innovation rather than dealing with data integration and processing challenges.
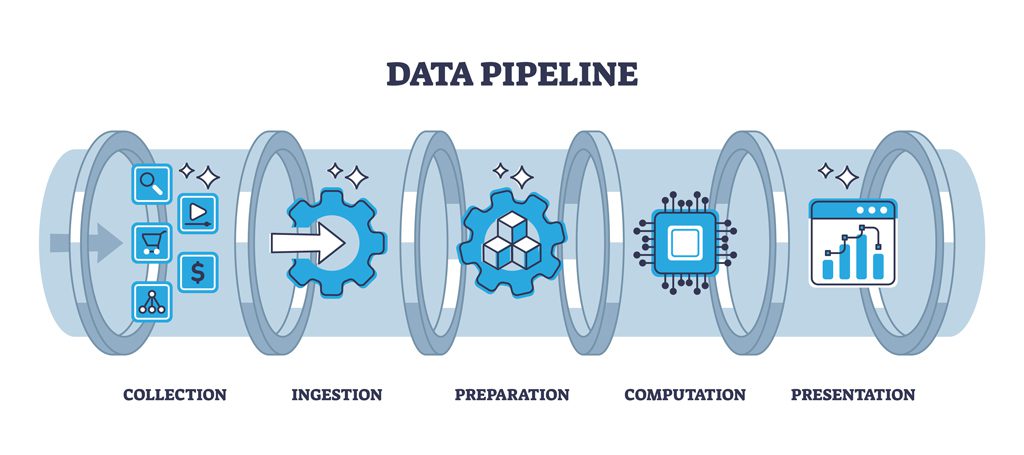
What are the components of a typical data pipeline?
A typical data pipeline consists of several key components that work together to ensure the smooth flow of data from its source to the desired destination. These components play different roles in processing, transforming, and managing the data throughout the pipeline. Here are some key components of a data pipeline:
- Data sources: These are the systems or applications where the data originates. Examples include relational databases, NoSQL databases, data warehouses, logs, spreadsheets, social media platforms and IoT devices.
- Data ingestion: This involves retrieving data from various sources, which may include databases, APIs, files, or streaming platforms.
- Data transformation: This step involves cleaning, validating, and transforming the data into a standardized format or structure suitable for analysis or storage.
- Data loading: The transformed data is loaded into a target destination, which could be a data warehouse, database, or cloud storage platform.
- Orchestration: This component manages the overall workflow and scheduling of the pipeline, ensuring the proper execution and coordination of data processing tasks.
What technologies are commonly used for building data pipelines?
There are various technologies available for building data pipelines, depending on the specific requirements and preferences of the organization. You would choose the right set of tools and technologies based on the data requirements, integration capabilities, cost, future scalability, and fault tolerance. Here are some commonly used technologies:
- Extract, Transform, Load (ETL) tools: These tools provide a graphical interface to design and execute data pipelines, offering functionalities for data extraction, transformation, and loading.
- Apache Kafka: A distributed streaming platform used for building real-time data pipelines and event-driven architectures.
- Apache Airflow: An open-source platform for orchestrating and scheduling complex workflows, including data pipelines.
- Cloud-based services: Cloud providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer managed services such as AWS Glue, Azure Data Factory, and GCP Dataflow which simplify the development and management of data pipelines.
What are some best practices for designing and maintaining data pipelines?
Designing and maintaining data pipelines requires careful consideration and adherence to best practices to ensure optimal performance, reliability, and data integrity. Here are a few best practices for data pipeline design and maintenance:
- Plan and define clear objectives for your data pipeline, considering the specific needs and goals of your organization.
- Ensure data quality by implementing data validation and error handling mechanisms.
- Monitor the pipeline’s performance, including data latency, throughput, and error rates, and establish alerting and logging systems. Implement automated alerts to notify the team of any problems.
- Implement data security measures to protect sensitive information during transit and storage.
- Use version control for pipeline code and configuration to enable reproducibility and traceability.
- Regularly review and optimize the pipeline to accommodate changing data sources, transformations, and scalability requirements. Conduct regular load testing to ensure the pipeline can handle peak loads and unexpected spikes in traffic.
- Implement a disaster recovery plan to ensure that the pipeline can quickly recover from failures or outages.
- Implement user version control to track changes to the pipeline and document the changes.
- Document the pipeline’s architecture, dependencies, and data lineage for future reference and troubleshooting.
How can data pipelines be scaled for handling larger data volumes?
The pipelines need to be future-proof, scalable, and adaptable to meet the increasing data volumes and processing requirements. Scalable pipelines promote fault tolerance by distributing the workload, ensuring that failures or resource constraints in one component do not affect the entire pipeline.
Here are some ways organizations can scale the pipelines:
- Employing distributed computing technologies that enable parallel processing, such as Apache Spark or Hadoop.
- Leveraging cloud-based services that provide auto-scaling capabilities, allowing the pipeline to dynamically adjust its resources based on demand.
- Optimizing data processing algorithms and techniques to improve efficiency and reduce bottlenecks.
- Partitioning data and parallelizing processing tasks to distribute the workload across multiple nodes or machines.
How can data pipeline failures or errors be handled?
Failures and errors are inevitable in any complex system, and data pipelines are no exception. When failures occur, they can disrupt the flow of data, compromise data integrity, and lead to costly delays or errors in downstream processes. Proper error handling ensures that data inconsistencies are detected and resolved promptly, minimizing the impact on data quality and downstream analytics. It also helps in maintaining the overall reliability and availability of the pipeline, enabling efficient data processing, and reducing the risk of costly disruptions to business operations.
Here are some ways the pipeline errors can be addressed:
- Set up alerts and notifications to detect failures or anomalies in the pipeline’s execution.
- Implement retry mechanisms to automatically rerun failed tasks or stages.
- Log detailed error information for troubleshooting and debugging purposes.
- Implement data validation and quality checks at various stages of the pipeline to detect and handle data inconsistencies or anomalies.
- Design fault-tolerant architectures that can recover from failures and ensure data integrity.
Data pipelines serve as the backbone of modern data engineering, facilitating the seamless flow of data for analysis, reporting, and decision-making purposes. By understanding the importance, components, technologies, and best practices associated with data pipelines, organizations can unlock the true potential of their data assets. As data volumes continue to grow, scalability considerations become vital, requiring organizations to adopt advanced technologies and optimization techniques. With the right approach and adherence to best practices, data pipelines can empower organizations to harness the power of their data and gain a competitive edge in today’s data-driven world.
